I have written about my participation in Facebook hacker cup 2021 in a medium blog post.
https://shadek07.medium.com/facebook-hacker-cup-2021-experience-519f594bec7e

I have written about my participation in Facebook hacker cup 2021 in a medium blog post.
https://shadek07.medium.com/facebook-hacker-cup-2021-experience-519f594bec7e
Problem link: Alternate Odd Even
Problem summary:
Find the K’th number from a positive increasing sequence of numbers such that their digits in a number alternate being odd and even.
Key facts:
My Approach:
First, find the number of digits that the K’th number will have:
It is smallest d such that
![]()
Let’s define N based on the d we just defined:
![]()
It is now evident that, the N’th smallest number having d digits is the answer of our problem. Now the question is: how do we find the N’th smallest suitable number having d digits? We can start iteratively starting from MSB (position d-1, LSB position is 0). In every bit positions we try eligible digits in increasing order and see how many numbers we can make with i’th position containing a digit say 4. The purpose of this calculation is to identify a digit in every i’th position such that our N’th smallest number will definitely have that number.
My code during the contest and it passed system test.
You can check the details of this marathon match in topcoder site: https://www.topcoder.com/challenges/82eb883d-85e9-442f-b0eb-91631d3d2a8f?tab=details
Problem Summary
You are given a 2D grid containing few holes, number blocks and empty cells. Your task is to move numbered cells to any hole using Slide or Move operations. Along the way, your goal is to maximize game score based on certain defined rules.
My Approach
My approach was to use simulated annealing (SA). In every iteration of the SA, I swapped the position of two numbered cells from an ordered list of numbered cells. This ordered list represents the order in which I want to move/slide blocks to holes one by one and one at a time.
Now my score boosted up after few optimization on baseline SA.
A demo of my solution for one of the test cases is below.
My code and along with other resources (including other competitor’s approaches) of this match can be found in my Topcoder repository
Here is another blog article on this match.
Some contestants used Beam Search in this match. Here is the wiki book link for that.
I have been using Topcoder java applet (ContestAppletProd.jnlp) for SRM competitions for over a year in Ubuntu 18.04. Suddenly, one day it stopped working showing me the following error.


To solve this issue, open java security configuration file using following command:
sudo vim /etc/java-*-openjdk/security/java.security
then search for a line similar to the following and comment it out and save the file (:wq command in vim).
jdk.jar.disabledAlgorithms=MD2, MD5, RSA keySize < 1024If you do that, your jnlp file will open fine with this dialog and you have to prompt that you trust this jnlp file and trust topcoder.com (haha)

Reference:
This was my fourth match in Topcoder data science marathon. If you don’t know what a data science marathon match is, here is a short description.
Marathon match runs for about a week. Each participant can submit their code during this period as many times as they want and only the last submission is considered for scoring.
Now regarding the type of problem you will be given in Marathon match: There is no universal optimal solution to the problem you are given. Your task is to optimize the solution as much as you can based on heuristics, advanced data structure and algorithm, genetic algorithm, machine learning algorithm, probability, statistics and so on.
Marathon Match 125
In this match, you were to solve a square grid to make as many horizontal, vertical or diagonal lines as possible with length of at least 5 grids of same color. At the end of every move three random balls with random colors will appear in the board. In each move, you can only move a ball from its position to an empty position by following a 4-connected path of empty squares.
Full problem statement: https://www.topcoder.com/challenges/39f57908-803c-4b69-b208-4fc03717ab12
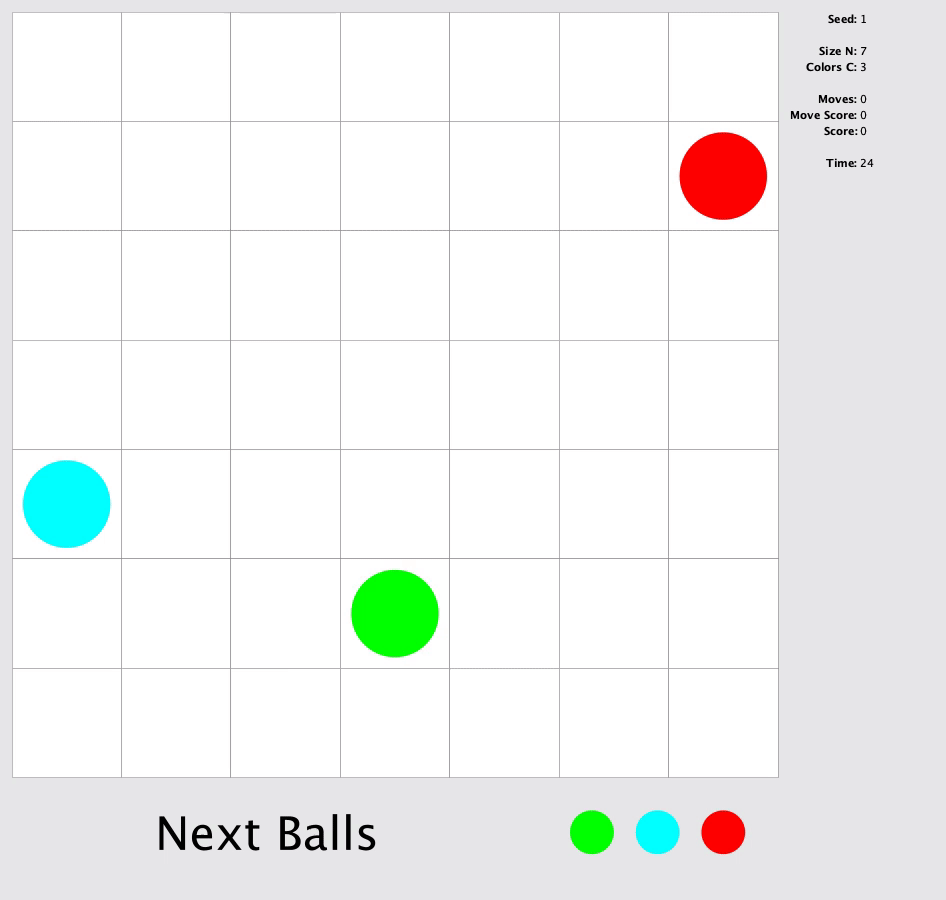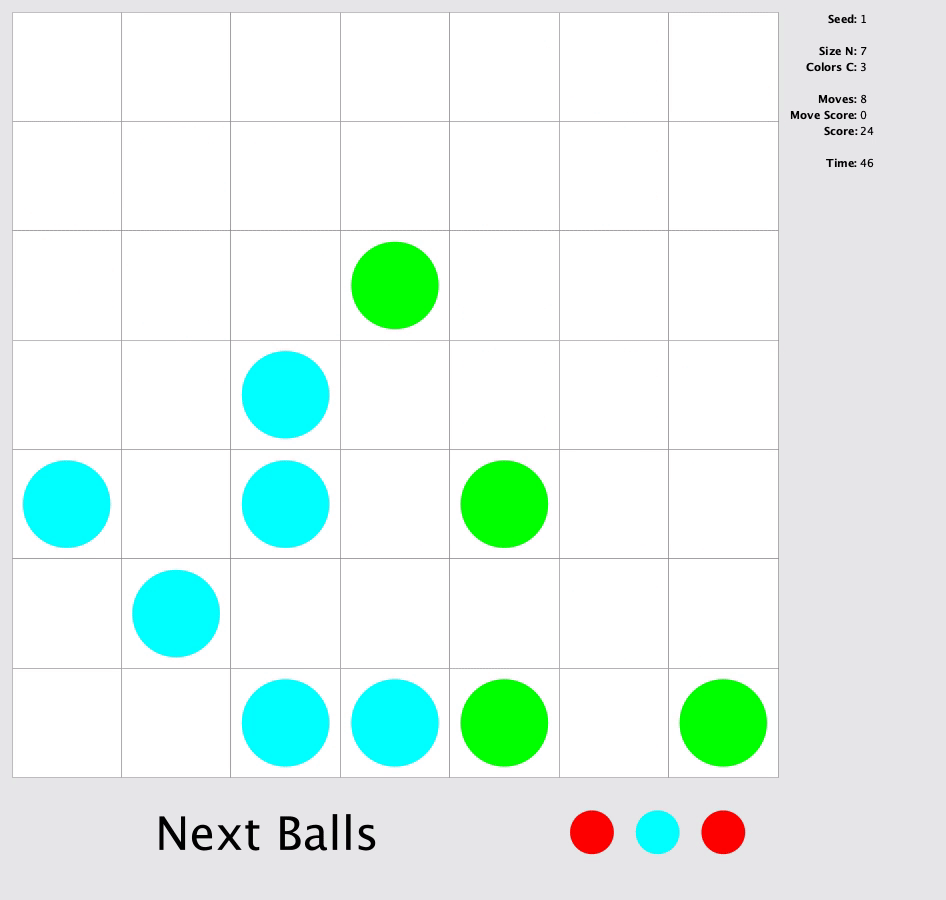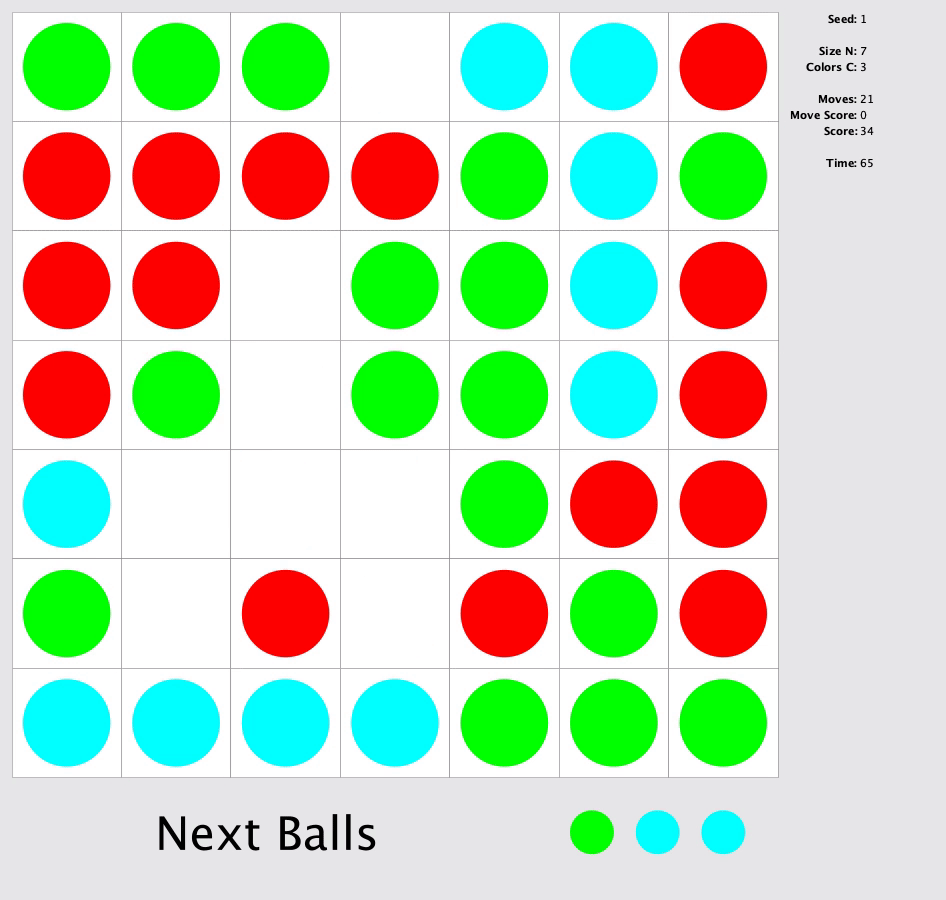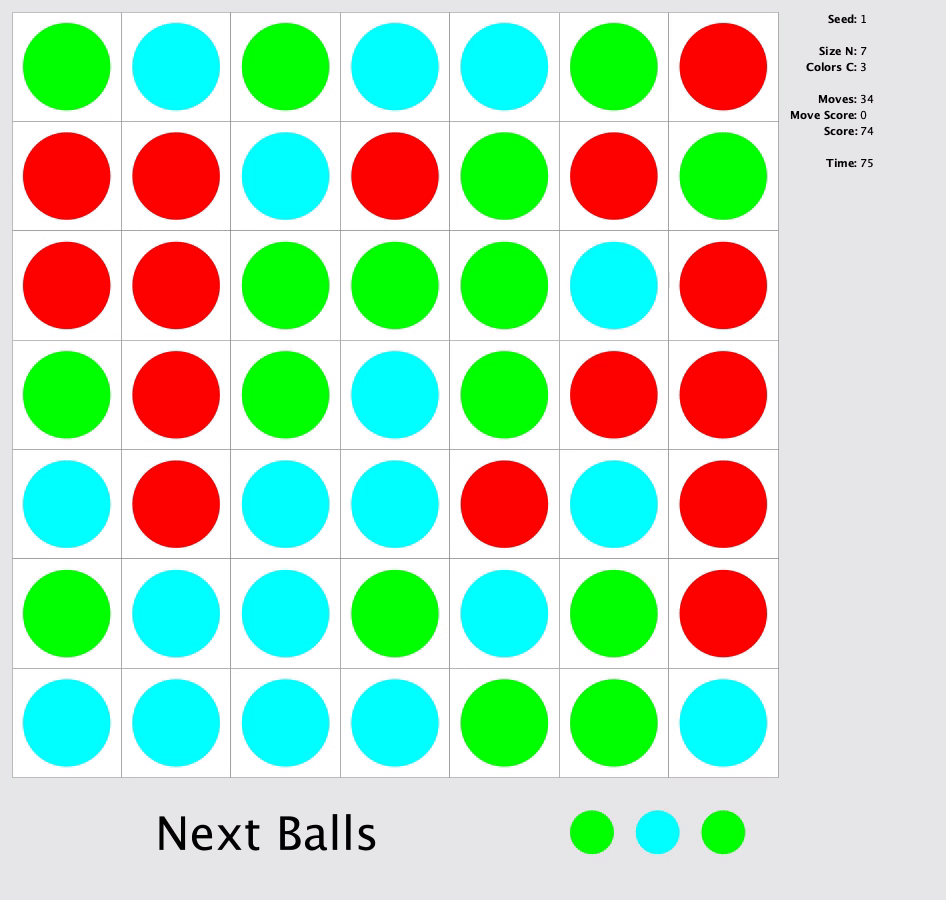
My Approach
My approach was to evaluate the board using a scoring function for every valid moves on the current grid and choose a move that leads to maximum score.
The score of a board is sum of scores coming from every possible grid segment of 5 length (horizontally, vertically or diagonally). In my solution, I didn’t consider diagonal segments as they block balls to move in the grid.
Now the scoring of a single segment is done by counting frequency of colors in that segment. The score is exponentially related to count of dominant color minus the count of other colors)
Now regarding optimization of time so that my code can execute as many moves as possible: I calculated the base score of the current grid before each move and stored all segment scores. Now each candidate move, affects only the segments that include either (fromX, fromY) cell or (toX, toY) cell. So to calculate the score of the board resulting from the candidate move, I only calculated those segments that are affected and adding all those segment scores from base score that ARE not affected.
My code submission and other materials on this match can be found here.
Case Study
After every Data science marathon match in Topcoder, the organizer provides all submissions of codes in a zip file. After extracting this file, you will see lot of individual submissions as zip file. So to see the solution of each submission, I had to unzip each submission and see the code as languages such as c++, python, csharp or c. This is time consuming. I wanted to combine all language specific submissions into a single file so that I don’t have to unzip back and forth to see code.
Solution
First I made a script to unzip all zip submissions into separate directories.
for file in *.zip
do
directory="${file%.zip}"
unzip "$file" -d "$directory"
done
The above code segment is stored as command.sh
The commands to execute this file:
chmod +x command.sh ./command.sh
These commands will unzip all zip files and put unzip contents in newly created directories.
Next we want to extract all c++ files in those sub-directories and concatenate all contents in a single file named allcpp.txt
The command for that is
find . -type f -name "*.cpp" -exec cat {} + >allcpp.txt
The same is for concatenating all python and csharp files:
find . -type f -name "*.py" -exec cat {} + >allpy.txt
find . -type f -name "*.cs" -exec cat {} + >allcs.txt
Reference:
https://stackoverflow.com/questions/2374772/unzip-all-files-in-a-directory/29248777
https://www.javatpoint.com/steps-to-write-and-execute-a-shell-script
Problem description here PoisonedSwamp
You should definitely know that this is a graph search problem. You can apply either DFS or BFS. However, the main challenge is to define the state meaning the vertex/node of this graph search problem. One key observation is that, you have to take poison count into consideration while you are visiting vertices/states.
So basically 3 parameters define a state: row number(x), column number(y), poison count acquired so far after stepping into cell(x,y) since the traversal started from cell(0,0). Another thing to note that, we don’t need to take care of poison count for more than 10 because the traveler is gonna die if he acquires >= 10 poisons.
I have implemented this using queue, in fact priority queue (it is not necessary as total state space is not so high). It is possible to solve this problem by a recursive dfs too.
My code during contest: https://community.topcoder.com/stat?c=problem_solution&rm=335435&rd=18497&pm=16768&cr=23058599
Topcoder achieved a milestone by arranging 800 Single Round Algorithm Matches (SRM) to the coder all over the world. Topcoder arranged a virtual party before this 800th match. Among this 800 matches, I participated in over 150 matches. (See my Topcoder profile). Thank you Topcoder for helping me improve my coding skill.
Let’s get back to the problem. This problem was worth 400 points. Please take a look at the problem statement as I am not gonna repeat the problem statement.

Look at the above picture to visualize this problem. As like this picture, our goal is to get letter ‘c’ (cherry) in all reels.
Key insights from this problem:
From these two constraints, we know that there could be maximum 10*10*10*10*10 = 10^5 different display strings you will see based on positions of the fruits although two different configurations might end up with same display string as there could be duplicate letters in a reel.
My approach for this problem is to play the slot machine rounds and keeping track of configurations in a map or dictionary. If a configuration repeats before getting a jackpot, that basically means the game entered into a cycle and we can return “impossible” in this case. Each configuration corresponds to a set of position indices of current display letters from all reels. Now the question is – how to store these configurations in map? My approach is to use unique letters to denote each index across all reels. For example ‘a’ is for index 0, ‘b’ is for index 1 and so on. The good thing is we will never run out of letters to represent indices as there would be maximum 10 letters (meaning 10 positions) in each reel. Remember that, this configuration letters are different from the letters in each reel.
After each round of play, we have to adjust the positions for next round. See the code below for a better understanding of my approach.
#include<bits/stdc++.h>
using namespace std;
class SlotMachineHacking {
public:
int win(vector reels, vector steps) {
map uniq_configs;
string jackpot = ""; //jackpot string: all 'c'
int i,j,k;
for(i = 0;i<reels.size();i++)
{
jackpot = jackpot + 'c';
}
int cnt = 0;
int n = reels.size();
int pos[n]; //indices of current display letters for all reel strings
for(i=0;i<n;i++)
{
pos[i] = 0;
}
auto newpos = [&pos, &reels, &steps](int n){
int i;
for(i=0;i<n;i++){
pos[i] = (pos[i]+ steps[i])%reels[i].size();
}
};
while (true){
string curr_display = "";
newpos(n);
for(i=0;i<n;i++)
{
curr_display += reels[i][pos[i]];
}
if(curr_display == jackpot) //current display matches jackpot
return cnt;
string curr_config= "";
for(i = 0;i<n;i++){
curr_config = curr_config + char(('a'+pos[i]));
}
if(uniq_configs[curr_config])
return -1;
uniq_configs[curr_config] = 1;
cnt += 1;
}
return -1;
}
};
In the above code you will see a c++ closure defined.
Another approach is to run the simulation for 10^5 times without keeping a map
more specifically,
number of rounds, R = Length(reels[0])*Length(reels[1])*…..Length(reels[n-1]);
n is total number of reels.
So if you don’t hit jackpot during this many rounds, you will never hit jackpot. Because if you do not enter into cycle during this many rounds, you will cycle in the very next round (i.e R+1‘th round)
References
1. image source
In this vim file editing video, I have shown how to edit a wrong file to make it same as the correct one. For specifically, the wrong file name in the demo was broken_fizzbuzz.py and correct file name was fizzbuzz.py. The demo was shown in a course offered by mit (link below).
The important vim commands used in this video are as follows:

The vimrc file that I had while making this video: https://github.com/Shadek07/vimrc/blob/master/.vimrc_Feb2021
References:
1. (https://github.com/phw/peek) to record screen
2. Screenkey to show keystroke on the screen (https://gitlab.com/screenkey/screenkey). Important command pkill -f screenkey to kill screenkey program after you are done
3. https://missing.csail.mit.edu/2020/editors/.
Let’s say, you have opened two vim windows via :split’ command. Now, how do you want to copy code segment from one window to another? Watch the video below.
Here, text was copied from solver.cpp file to SoccerTournament.cpp file.
The commands used in the video have been executed in several mode. Normal mode, Visual line mode (Capital V), Command mode (colon :).
All commands used for copy-paste task are listed below with short description.

Some resources I used:
https://missing.csail.mit.edu/2020/editors/
The following exercise is taken from this lecture.
Exercise:
Find your average, median, and max system boot time over the last ten boots. Use journalctl on Linux and log show on macOS, and look for log timestamps near the beginning and end of each boot. On Linux, they may look something like:
Logs begin at ...
and
systemd[577]: Startup finished in ...Solution: The complete command for the solution is below:
journalctl | grep '.*Startup finished in.*' | \
grep -E '^.*Startup finished in [0-9]+ms.$' | \
sed -E 's/^.*in ([0-9]+)ms.$/\1/' | tail -n10 | \
R --slave -e 'x <- scan(file="stdin", quiet=TRUE); summary(x)'
After 3rd line of command, the pipe output is following:
499
577
457
896
706
748
599
611
304
376
Then R code section takes the above list to show summary with the following format:
Min. 1st Qu. Median Mean 3rd Qu. Max.
304.0 467.5 588.0 577.3 682.2 896.0
One thing to note that, in this exercise we only considered boot time that took time is ms format, not in s format.
Sep 16 14:47:08 shadek-pc systemd[1082]: Startup finished in 599ms.
Sep 28 22:21:46 shadek-pc systemd[1126]: Startup finished in 1.861s.
Sep 28 22:22:09 shadek-pc systemd[1]: Startup finished in 6.057s (kernel) + 1min 8.510s (userspace) = 1min 14.567s.
In the above segment, solution command only took care of format in first line.
The following exercise is taken from Data Wrangling lecture of “Missing semester- MIT 2020” Course. Lecture link
Question:
Find the number of words (in /usr/share/dict/words) that contain at least three as and don’t have a 's ending. What are the three most common last two letters of those words? sed’s y command, or the tr program, may help you with case insensitivity. How many of those two-letter combinations are there? And for a challenge: which combinations do not occur?
Solution for:
Find the number of words (in /usr/share/dict/words) that contain at least three as and don’t have a 's ending.
cat /usr/share/dict/words | sed -E 'y/A/a/' | grep -E '.*a{1,}.*a{1,}.*a{1,}.*' | grep -v ".*'s" | wc -l
Solution for:
What are the three most common last two letters of those words?
cat /usr/share/dict/words | sed -E 'y/A/a/' | grep -E '.*a{1,}.*a{1,}.*a{1,}.*' | grep -v ".*'s" | sed -E 's/.*(..)/\1/' | sort | uniq -c | sort -nk1,1 | tail -n3
The output from the last pipe of the above command is:
54 as
63 ns
101 an
Solution for:
How many of those two-letter combinations are there?
cat /usr/share/dict/words | sed -E 'y/A/a/' | grep -E '.*a{1,}.*a{1,}.*a{1,}.*' | grep -v ".*'s" | sed -E 's/.*(..)/\1/' | sort | uniq -c | wc -l
The result is:
111
Solution for:
And for a challenge: which combinations do not occur?
(generate all possible two letter combinations)
(subtraction. only shows two letter combinations from all.txt that belong only to all.txt and not in combinations.txt)
Result of ‘comm -23 all.txt combinations.txt | wc -l‘ is 565 which is (26*26 – 111)
References:
history >> commands.log
Snapshot of commands.log is the following:
1005 cd ..
1006 scp -r ./client/app/index.html name@204.48.23.126:/home/name/project/client/app
1007 cd client
1008 bower install --save angular-chart.js
1009 grunt serve
1010 lsof -i :9000
1011 kill 2152
cat commands.log | sed -E 's/^\ [0-9]+\ (.*)$/\1/' | sort | uniq -c | sort -nk1,1 | tail -n10
Explanation of the above command:
‘sed‘ command captures the pattern in each line of commands.log and replaces it only by the command, by ignoring command number. ‘sort‘ command sorts all commands. ‘uniq -c‘ counts how many times each command was executed. Data after ‘uniq -c‘ execution will look like the following:
3 command1
11 command2
......
‘sort -nk1,1‘ sorts each of the above line by only count (which is in first column) of each command. and then ‘tail -n10‘ shows top 10 commands with most counts.
I joined HDI lab in last Spring. Last spring passed by getting to know about the lab and the research topics. I became more interested in the lab after knowing that the research in the lab is being conducted at the cross section of Artificial general Intelligence, Machine Learning, Deep Neural Network and Reinforcement learning. My summer in the lab started with replicating world model paper. World model is a phenomenal paper on reinforcement learning environment training. It was not quite easy for me to reproduce world model experiments when I did not have (I still do not) enough knowledge on Reinforcement learning and Application of Neural network. In one of our HDI lab seminar I confused popular PPO algorithm with world model concept. There were many underlying concepts before attempting to replicate: ml-agents, Open-AI gym, Variational autoencoder etc. Once I became familiar with all of those, replicating experiments became easier.
One of several of my plans in summer was to complete three courses on Reinforcement learning in Udemy. When I started coding for those courses, things became much clearer.
After replicating world model, my next plan was to apply world model for Visual pushblock game. Visual pushblock is a game environment built by Unity3d company. First I stumbled upon on making executable visual pushblock game env in Unity3d. I took me couple of days to figure out why pushblock unity env was not behaving properly in python. Next I went deep into source code of world model to understand code and then change code to use unity3d environment for implementation. One component of this implementation is to train Variational autoencoder(VAE). After training VAE, I found out the vae training was successful. Reconstructed images was almost identical to original images. Then I made interactive demo of VAE using interactive source code of worldmodel. For this interactive demo, I had to write code in javascript, python and html. At some stage of making this demo, I had no clue how the demo is supposed to work. But gladly, after spending 2-3 days of hard work I was able to make interactive VAE demo. Then I finished other parts of the experiment.
My major plan for Fall 2019 is to compare multiple experiments of worldmodel with different settings, get deep understanding of go-explore system built by Uber-AI team and use that for Visual Pushblock game to see performance improvement. I also have plan to learn about Imitation and curriculum learning, .
I was working on implementation of “World Model” paper (https://github.com/hardmaru/WorldModelsExperiments) for Visual PushBlock Unity 3d game. One part of that implementation is to have a Variational Autoencoder (VAE) model to have a compressed representation of each visual frame (64x64x3) of the game. Compressed representation was used in one of the versions of experiment in World Model. Source code for World model experiment of Visual PushBlock game: https://github.com/Shadek07/WorldModel_VisualPushBlock
To start off the VAE part, I created a training dataset using Unity3d VisualPushBlock environment. The dataset had a total of 7000 episodes of pushblock game. Each episode consists of maximum 1001 visual frames unless the episode is over because of agent of the game reached the target zone of the pushblock game environment. This dataset creation was performed by running extract.py file. After that, we need to execute vae_train.py to train vae using the dataset. I did set a hidden vector size of 64 to represent each frame during training.
Second part of VAE component is i) reconstruction of an image frame using encoder and decoder of VAE by providing random frame from training dataset, ii) visualize the effect of each hidden dimension into the reconstruction of frame. For this visualization part, I used source code of interactive worldmodel experiment. (https://worldmodels.github.io/, https://github.com/worldmodels/worldmodels.github.io). I had to create data folder for visual pushblock for this visualization. The folder contains json files (json has mu and sigma for each input image each having dimension of 64) and image files for 1000 visual frames. I also had to have a js file containing all the decoder (which is a part of VAE) weight parameters (basically deconvolutional kernel and bias params) of trained VAE. Have a look at the attached visualization in the following video. At the bottom of this web page, you can interact with the demo by changing slider, by randomly choosing images, by randomly choosing z vector.
Each slider in the video represents a specific dimension out of 64 dimensions of hidden vector. These dimensions are chosen by trial and error which have significant impact in the reconstruction of image. As each of the sliders are being changed, please take a look at the image on the right side to see the effect.
Github repository for this interactive demo is here: https://github.com/Shadek07/interactive-visualpushblock
I trained worldmodel carracing on a PC having less than 64 (it was 32) CPU cores. I have also changed some parameters in the author’s implementation so that program does not produce “Memory out of bound” error. To reproduce worldmodel experiment, I took help from this blog post: http://blog.otoro.net//2018/06/09/world-models-experiments/
First, Create an anaconda environment with python version 3.6
In Linux, here are some sources about installing cuda:
Next step, Download worldmodel from github
Install following Ubuntu packages:
In the following steps, Install following python packages by pip
Worldmodel experiment requires having a machine of alteast 200GB of RAM. My lab machine has only 64 GB of RAM. To get rid of memory error I had to change vae_train.py file: (add this line ‘num_npzepisode_to_use = 1000’ (without quatation) at the top of file, then change line number 63 to: filelist = filelist[0:num_npzepisode_to_use]).
Change some python files before you run that files to utilize multiple gpus:
If you want to run this experiment in server PC, create a tmux session first and then execute commands there (for example: tmux a -t carracing)
If your PC doesn’t have 64 CPU cores, you have to edit extract.bash file. Default code assumes that you have >= 64 core CPUs. Run the command (bash extract.bash) four times. Each time choose only 16 CPU cores (1 to 16, then 17 to 32, then 33 to 48 then 49 to 64))
After that execute bash gpu_jobs.bash. Then move json files that were being created by following commands:
Add this line: os.environ[“CUDA_VISIBLE_DEVICES”]=””, inside train.py to stop using gpu for this job: bash gce_train.bash
Finally test the trained model by executing the following:
Now you can update files of your local carracing/log folder with the trained json file in the respective folder residing in the server. Then you can run python model.py render log/carracing.cma.16.64.best.json to find performance of trained model.
Github link of project containing trained log folder is here: https://github.com/Shadek07/WorldModel
Performance Evaluation of experiment:
The reported average cumulative reward of best performing agent in the worldmodel paper was 900.46. But in my experiment, best performing agent had avg cumulative reward of 754.
Some figures and videos of my experiment are given below:


A gif snapshot of rendered environment when running python model.py render log/carracing.cma.16.64.best.json

As part of my worldmodel experiment, I wanted to create Unity environment executable of VisualPushBlock game. Visual Push Block is different from PushBlock where in VisualPushBlock environment will be provided as first person image of size (1x84x84x3). I was having issue of generating visual observation of pushBlock in python. The issue is that: after I load unity environment in python, a visual unity environment opens up but Any code below the opening of UnityEnv was not executed. So I could not get data of visual image via python. Here is what I was trying to do:
from mlagents.envs import UnityEnvironment
env_name = ‘./VisualPushBlock/Unity Environment.exe’
env = UnityEnvironment(file_name=env_name)
default_brain = env.brain_names[0]
brain = env.brains[default_brain]
print(brain)
print(brain.camera_resolutions)
Here, the last two print statements were not being executed.
To solve this problem, I basically had to change the way I created Unity environment executable by changing several parameters and adding a few items while creating environment executable. First of all, “Control checkbox” of VisualPushBlock academy brain has to be checked to make the brain external.

Second, Under “visual area” hierarchy there is ‘Agent’ object. Agent object has a segment of ‘Push Agent basics’. Change brain in that segment to ‘VisualPushBlockLearning’ instead of ‘VisualPushBlockPlayer’. See figure below.

Next, Click on ‘VisualPushBlockLearning’ within brains hierarchy. On the parameter section, change vector observation space size to 0 and add a visual observation of size 84×84.

When creating executable (with env_name.86_64 extension) for linux, a separate folder is also get created named as env_name_data. You need to move this folder too where you want to execute .86_64 file.
Problem link – InterleavingParenthesisDiv2
This is a classic dynamic programming (dp) problem. Before discussing dp, let’s try to derive some additional properties of balanced parenthesis along with basic properties.
The length of a balanced parenthesis sequence is even. From one basic property we know: If “X” is a correct sequence, then “(X)” is a correct sequence. We see that, each time length of ‘X’ is incremented by 2 [one left ‘(‘ and one right ‘)’ ] and sequence starts from length 0. So parity remains even. Even concatenation of two correct sequences doesn’t change parity as sum of two even numbers is even. Another property is: number of left ‘(‘ and right ‘)’ parenthesis symbols in a balanced sequence are equal.
In line with problem statement, assume sz1 and sz2 are the lengths of input strings s1 and s2 respectively. We can’t create any balanced sequence if (sz1+sz2) is odd, based on above discussion. Let’s say S = s1+s2 (concatenation). We would get zero balanced sequence if number of left ‘(‘ and right ‘)’ parentheses symbols are not equal. Even if above two properties are satisfied for s1 and s2, we may not find any balanced sequence. For example, s1 = “)((”, s2 = “)”.
Important part of applying dp in this problem is understanding the following code snippet. We pass a balanced sequence p as input to this function:
void func(string s){
int counter = 0;
for(int i=0; i < s.size(); i++){
if(s[i] == '(')
counter++;
else
counter--;
}
}
Here, counter variable would never be negative at any stage of the iteration.
Let’s try to build a balanced sequence from scratch. We initially have an empty string S = “” and have a ‘counter’ variable initialized to 0. Each time we concatenate a ‘(‘ to S, counter is being incremented by 1 and decremented by 1 in case of concatenating a ‘)’. One thing to keep in mind that we can concatenate ‘)’ only when counter is positive (> 0) based on above code snippet.
Our dp state for this problem would be (counter, ind1, ind2). It defines the number of different balanced sequences that can be made if current counter value is counter and first ind1, ind2 symbols from s1 and s2 respectively have already been taken care of.
From state (counter, ind1, ind2), next possible states are:
(counter+1, ind1+1, ind2), when s1[ind1] is ‘(‘ and we concatenate it into S.
(counter+1, ind1, ind2+1), when s2[ind2] is ‘(‘ and we concatenate it into S.
(counter-1, ind1+1, ind2), when counter > 0, s1[ind1] is ‘)‘ and we concatenate it into S.
(counter-1, ind1, ind2+1), when counter > 0, s2[ind2] is ‘)‘ and we concatenate it into S.
Number of total balanced sequences for (counter, ind1, ind2) would be sum of balanced sequences of all four derived states. One crucial point of this problem is that input string s1 and s2 have to be processed sequentially left to right (i.e from index 0 to length-1). Because the order of the symbols from either s1 or s2 in the final balanced sequence should remain intact.
After processing both s1 and s2 completely, we will find a balanced sequence if counter is 0. That’s the base case. And the root of the all dp states would be (0,0,0).
C++ code is provided below:
#define M 1000000007
int dp[55][55][55];
int sz1,sz2;
string str1,str2;
int doit(int counter, int ind1, int ind2){
if(ind1 == sz1 && ind2 == sz2){
if (counter == 0) //found a correct sequence
return 1;
else return 0;
}
if(dp[counter][ind1][ind2] != -1){
return dp[counter][ind1][ind2];
}
int ans = dp[counter][ind1][ind2];
ans = 0;
//add left parenthesis from s1
if(counter < (sz1+sz2)/2 && ind1 < sz1 && str1[ind1] == '('){
ans = (ans + doit(counter+1, ind1+1, ind2))%M;;
}
//add left parenthesis from s2
if(counter < (sz1+sz2)/2 && ind2 < sz2 && str2[ind2] == '('){
ans = (ans + doit(counter+1, ind1, ind2+1))%M;
}
//add right parenthesis
if(counter > 0){
//from s1
if(ind1 < sz1 && str1[ind1] == ')'){
ans = (ans + doit(counter-1, ind1+1, ind2))%M;;
}
//from s2
if(ind2 < sz2 && str2[ind2] == ')'){
ans = (ans + doit(counter-1, ind1, ind2+1))%M;
}
}
dp[counter][ind1][ind2] = ans;
return ans;
}
class InterleavingParenthesisDiv2 {
public:
int countWays(string s1, string s2) {
sz1 = s1.size();
sz2 = s2.size();
//length of sequence odd, so return 0
if((sz1+sz2)%2 == 1)
return 0;
str1 = s1,str2=s2;
//initialize dp table with -1
memset(dp,-1,sizeof(dp));
return doit(0,0,0);
}
};
Download the problems from here: https://icpc.baylor.edu/worldfinals/problems/icpc2017.pdf
Discussion on two easy problems:
Problem F: (Posterize)
This problem can be solved using standard dynamic programming approach. One thing to notice in this problem is that only 256 (d) (0 to 255) different red values are possible and number of allowed red values (k) is at most d. This observation directs us to solve the problem using 2d DP table with dimension of 256 x 256.
Here is the code
In the code, mat[i][j] denotes the sum of squared error when current chosen red value in posterized image is i and number of distinct red values already chosen in the image is j. And we are only required to take care of red values from the input which are greater than i. The base case in the DP table is when we have used up all the allowed number of red values. In this case imagine that final chosen red value is prev. So from the input, all red values greater than prev will be replaced by prev.
Problem I: (Secret Chamber at Mount Rushmore)
The problem can be solved using Floyd-warshall algorithm to find the reachability between the letter pairs. Here is the code
1. Andrash and Stipendium (EGRANDR) [Problem link]
Simulate the problem description. Output is “No” if the student has failed in at least one subject or hasn’t got full score in at least one subject or the subject average is below 4. For all other cases, output is “Yes”.
Code
2. Chefland and Electricity (CHEFELEC) [Problem link]
Three possible cases to consider-
♦ string array starts with one or more 0’s (i.e 00001…)
All leftmost 0’s will be connected to the leftmost 1. Total length of wire needed in this case is the coordinate difference between first 0 with leftmost 1.
♦ string array ends with one or more 0’s (i.e ….10000)
All rightmost 0’s will be connected to the rightmost 1. Total length of wire needed in this case is the coordinate difference between last 0 with rightmost 1.
♦ string array contains some groups of 0’s surrounded by two 1’s in both side (i.e …10001…101..1001..)
These 0’s will be connected to either immediate left side 1 or immediate right side 1. More specifically, 0’s will be divided in at most two parts. Partition will be made in a position where we get minimum wire length. Left part of the group of 0’s connects with left 1 and right part of the group of 0’s connects with right 1. It is also possible that whole group of 0’s connects with either left 1 or right 1.
Code
3. Chef and Tetris (CHEFTET) [Problem link]
I solved this problem by backtracking with pruning.
What is the probable list of integers from which we get maximum integer such that all Ai‘s can be made equal to one of these integers? The list is quite small- {A1, A1+B1, A1+B2, A1+B1+B2}
Code
4. Chef and Robots Competition (CHEFARC) [Problem link]
This is a problem of finding min distance in 2D grid. I used BFS to find minimum number of moves needed to reach every grid cell for two robots separately from their initial positions. Now consider a particular grid cell (i,j). If 1st robot reaches this cell in x moves and 2nd robot reaches this cell in y moves, then minimum number of moves needed for both robots to be at cell (i,j) is P(i,j) = MAX(x,y). We need to find minimum from all P(i,j) ‘s [1 ≤ i ≤ N, 1 ≤ j ≤ M]
Code
